
Abstract
Overview
XPG-RL consists of two main components: (1) a perception pipeline, which processes fused RGB-D images to extract semantic and geometric context and builds a compact scene representation; and (2) an RL-based decision-making module, which takes this representation as input and learns a policy to predict adaptive thresholds. These thresholds guide the selection among priority-structured action candidates (e.g., target grasping, occlusion removal, and viewpoint adjustment), enabling context-aware and efficient action execution.
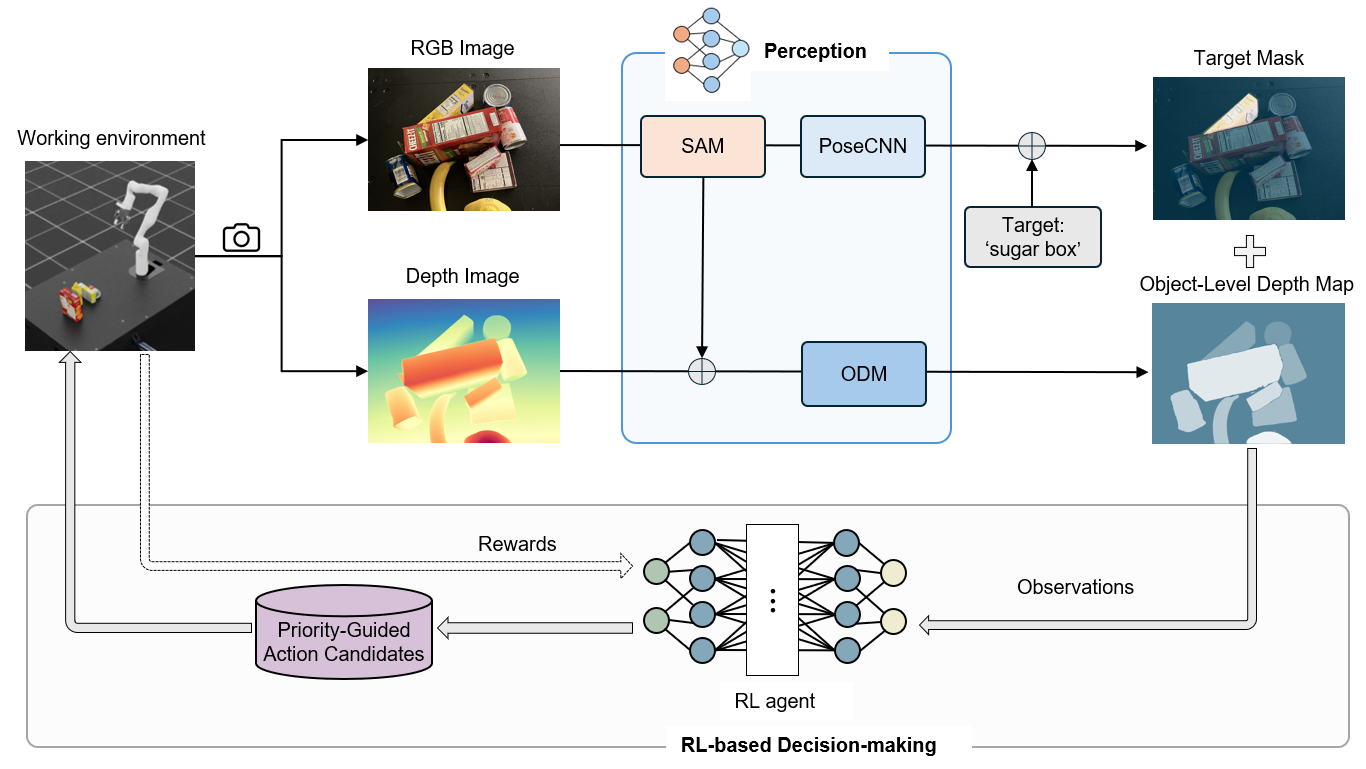
Priority-Guided Action Candidates
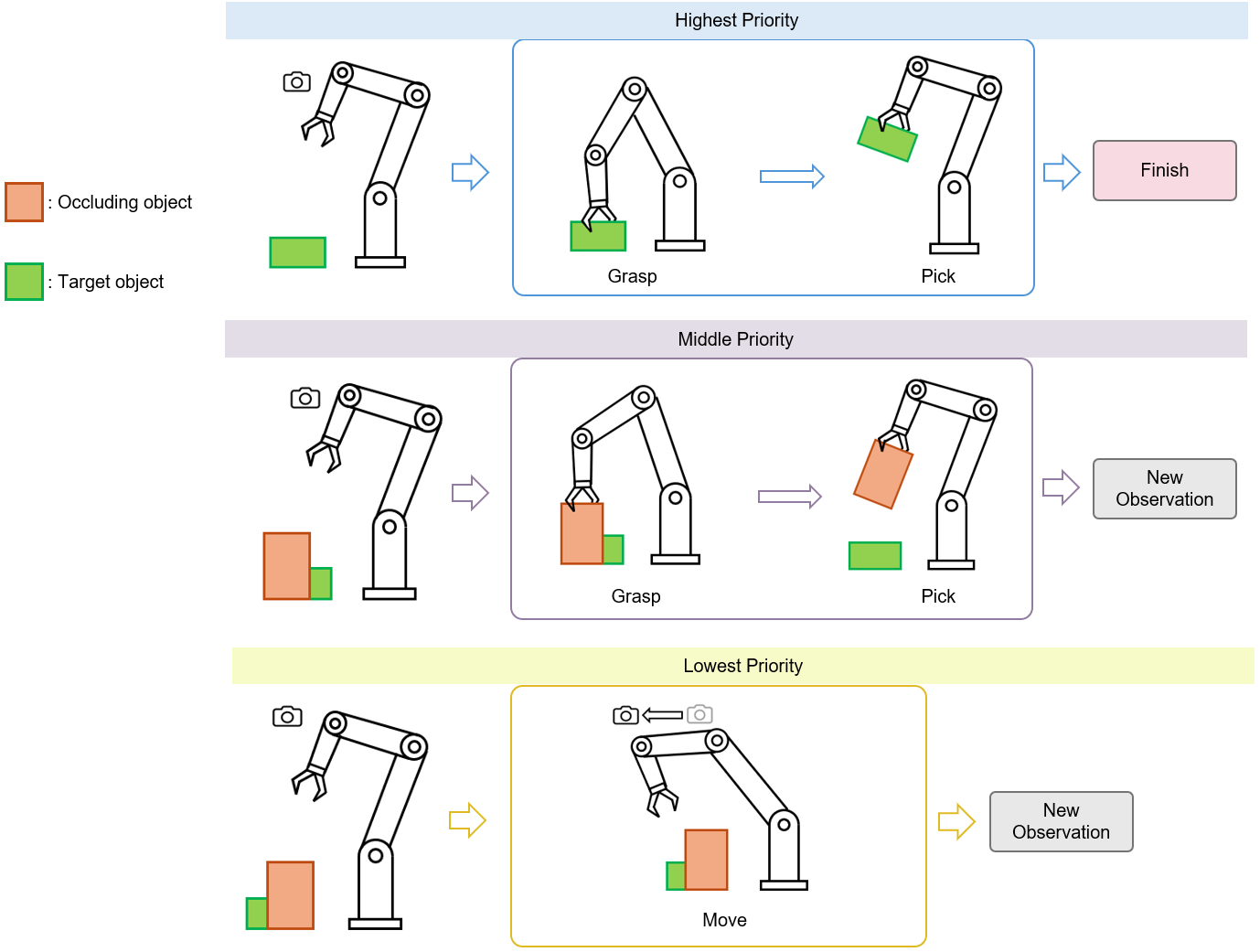
The action space consists of three discrete primitives—target grasping, occlusion removal, and viewpoint adjustment—ranked from highest to lowest priority. Learned thresholds govern switching between these actions, enabling the agent to make efficient, interpretable decisions by sequentially evaluating actions in priority order.
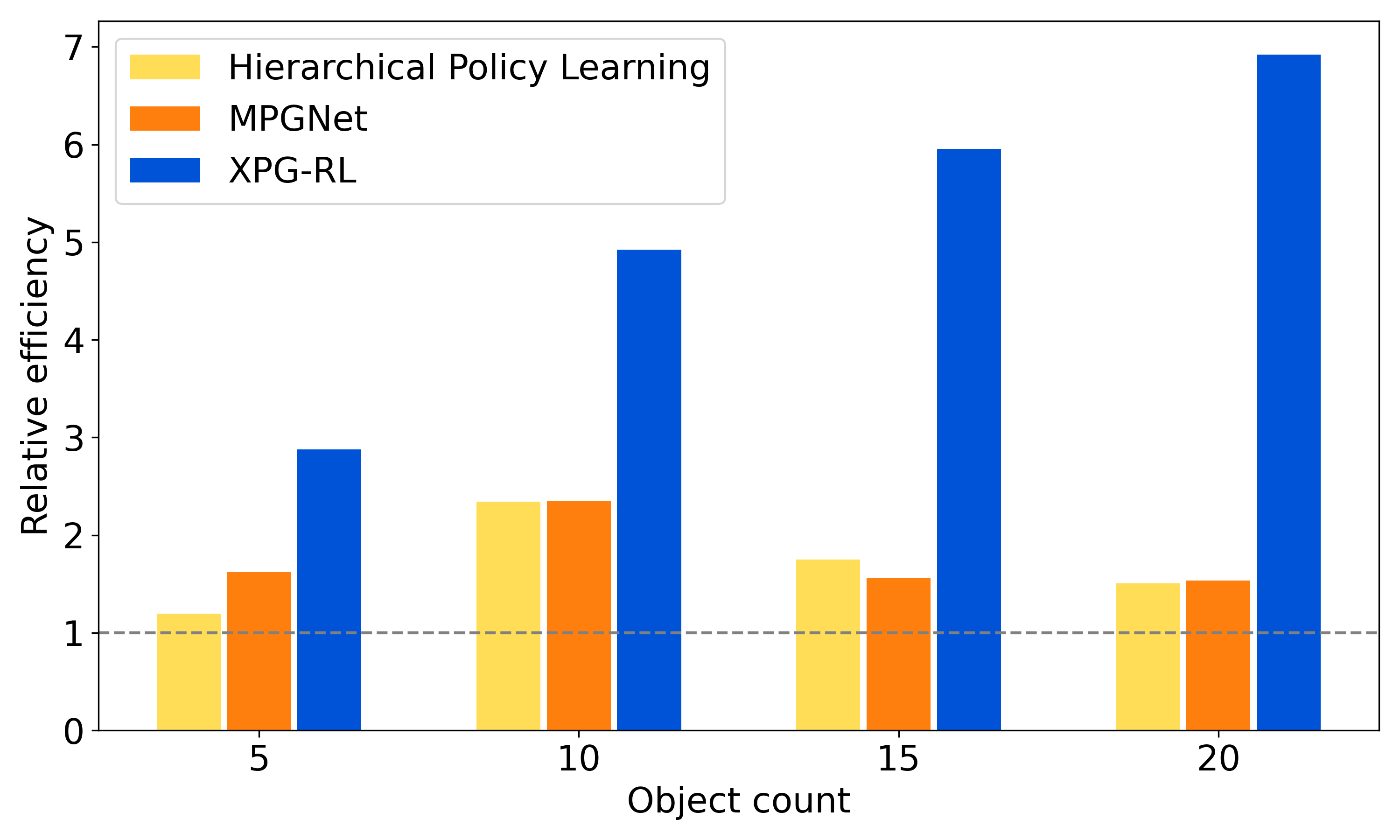
Results
XPG-RL outperforms baselines across all clutter levels, with relative efficiency gains widening as object count increases.
BibTeX
@article{zhang2025xpg,
title={Xpg-rl: Reinforcement learning with explainable priority guidance for efficiency-boosted mechanical search},
author={Zhang, Yiting and Li, Shichen and Shrestha, Elena},
journal={arXiv preprint arXiv:2504.20969},
year={2025}
}